Die Erlebnisstation „Describe Everything“ ist ein Demonstrator für Vision-Language-Modelle (VLM). Sie zeigt beispielhaft, wie Künstliche Intelligenz Bilder analysieren und in verständliche Sprache übersetzen kann.
Nutzerinnen und Nutzer laden ein Foto hoch und wählen zwischen drei Detailstufen:
Niedrig – ein knapper Überblick, ideal für schnelle Orientierung.
Mittel– ausführlichere Darstellung mit Kontext.
Hoch – präzise, tiefgehende Analyse, die auch kleinere Elemente erfasst.
So erleben Besucher:innen direkt, wie aus reinen Bilddaten strukturierte Informationen werden – und wie der Detaillierungsgrad den Nutzen und die Lesbarkeit verändert.
Anwendungsbereiche für Unternehmen
Die KI-Technologie der Smart Sketch Search hat zahlreiche praktische Anwendungen für Unternehmen
Automatisierte Schadensdokumentation und Schadenbewertung
Kurzfassung: Versicherer und Dienstleister lassen Fotos von Schäden (Fahrzeuge, Gebäude, Waren) automatisiert analysieren. Die KI identifiziert Schadensarten, schätzt Ausmaß/Kostenklassen, erzeugt standardisierte Befunde und priorisiert Fälle für manuelle Gutachter. So werden die Bearbeitungszeiten der Schadensmeldungen deutlich verkürzt und die Konsistenz erhöht.
Beispiel: Nach einem Hagelsturm lädt eine Kundin Fotos ihres beschädigten Dachs hoch. Die KI erkennt in Sekunden Bruchstellen, Wasserschäden und verschobene Dachlatten, klassifiziert den Schaden und erstellt automatisch einen Bericht fürs Schadensmanagement. Standardfälle werden direkt bearbeitet, komplexe Fälle gehen an eine Sachverständige – mit allen Bildauswertungen im System. Das beschleunigt die Bearbeitung, reduziert Rückfragen und schafft Freiraum für Fälle, die menschliche Expertise erfordern.
Barrierefreiheit für sehbehinderte Menschen
Wenn Sie Bilder auf Ihrer Website oder in sozialen Medien veröffentlichen, bleiben diese für blinde und sehbehinderte Menschen ohne Beschreibung unsichtbar. Vision-Language-Modelle können automatisch kurze oder detaillierte Textalternativen erstellen, die Screenreader direkt vorlesen. So erfahren Nutzerinnen und Nutzer, was auf dem Bild zu sehen ist – von Personen und Farben bis hin zu Handlungen.
Für Sie bedeutet das:
Zugänglichkeit ohne Zusatzaufwand – Beschreibungen entstehen automatisch.
Rechtssicherheit – Sie erfüllen gesetzliche Vorgaben zur Barrierefreiheit.
Flexibilität – Texte lassen sich je nach Kontext kürzen oder erweitern.
Im Vergleich zu manueller Texterstellung ist die KI-Lösung schneller, skalierbarer und konsistent in der Qualität.
Weitere Möglichkeiten zur Anwendung der VLM-Technologie:
Automatische Produktbeschreibungen im E-Commerce: Online-Shops müssen Produkte mit Beschreibungen und Merkmalen versehen, damit Kunden gezielt suchen und vergleichen können. Besonders bei großen Katalogen mit tausenden Artikeln ist die manuelle Erstellung aufwendig und kostenintensiv. Die KI liest Produktfotos aus und generiert automatisch präzise, verständliche Beschreibungen von Form, Farbe, Material oder Stil.
Textinhalte können von Suchmaschinen indexiert werden – Bilder allein nicht. Automatisch generierte Beschreibungen erhöhen so die Auffindbarkeit. Und Kunden können Produkte über Suchbegriffe oder Filter finden, die auf den Textbeschreibungen basieren, z. B. „rotes Sommerkleid aus Baumwolle“.
Automatisierte Analyse medizinischer Bilder: In der Radiologie werden täglich Tausende von Bilddaten erzeugt, beispielsweise Röntgenaufnahmen, CT-Scans oder MRT-Bilder.Die manuelle Auswertung dieser Bilder durch Fachpersonal ist zeitaufwendig und fehleranfällig.KI-Modelle, die auf Vision-Language-Modelle (VLMs) basieren, können diese Bilder analysieren und automatisch präzise Textbeschreibungen generieren.Diese Beschreibungen umfassen beispielsweise die Identifikation von Tumoren, Frakturen oder anderen Anomalien sowie deren Lage und Größe.
Der Vorteil:Textbeschreibungen bieten eine klare und nachvollziehbare Dokumentation der Befunde, die für spätere Vergleiche oder rechtliche Zwecke wichtig ist.Die generierten Textbeschreibungen können nahtlos in elektronische Gesundheitsakten (EHR-Systeme) integriert werden, was die Arbeitsabläufe im Krankenhaus optimiert.
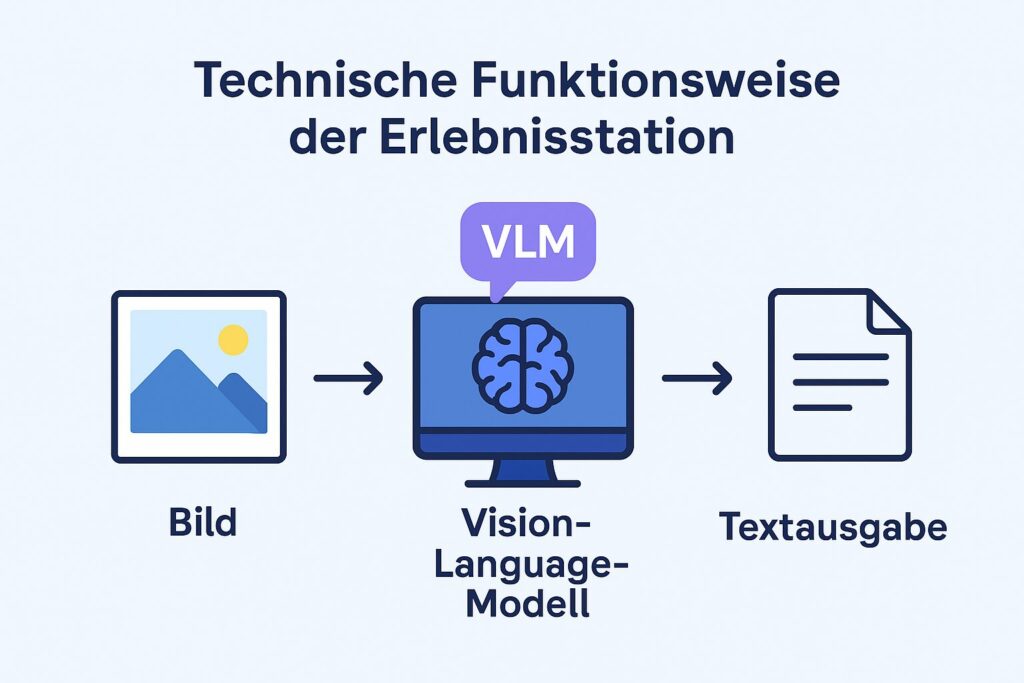
Technische Funktionsweise
Die Erlebnisstation basiert auf einem Vision-Language-Modell (VLM) – einer speziellen Form künstlicher Intelligenz, die Bildverarbeitung und Sprachverarbeitung kombiniert. Das System kann ein Bild nicht nur „sehen“, sondern es auch verstehen und in natürlichsprachige Sätze übersetzen.
Das Modell wurde auf Millionen von Bild-Text-Paaren trainiert. Dadurch hat es gelernt, Zusammenhänge zwischen visuellen Inhalten und ihrer sprachlichen Beschreibung zu erkennen. In der Praxis bedeutet das: Das VLM analysiert ein Bild, identifiziert darin enthaltene Objekte, Personen, Szenen, Farben oder Handlungen und formuliert daraus automatisch eine präzise und verständliche Beschreibung.
Ein zentrales Merkmal ist die lokale Ausführung: Das gesamte System läuft vollständig auf der vorhandenen Hardware vor Ort. Keine Bilddaten werden an externe Server gesendet – ein entscheidender Vorteil für Datensicherheit und die Einhaltung der DSGVO.
Dank der multimodalen Verarbeitung kann das VLM visuelle und sprachliche Informationen parallel verarbeiten. Das ermöglicht eine tiefere Interpretation: Die KI erkennt nicht nur, was auf einem Bild zu sehen ist, sondern kann auch den Kontext und die Beziehungen zwischen den Elementen verstehen.
Diese Technologie macht es möglich, Besucherinnen und Besuchern Inhalte intuitiv und barrierearm zugänglich zu machen – zum Beispiel durch automatisch generierte Bildbeschreibungen in deutscher Sprache.
Das VLM erreicht eine Genauigkeit von ca. 85-90% bei der Objekterkennung und kann komplexe Szenen meist korrekt beschreiben. Gelegentlich können Details falsch interpretiert oder übersehen werden.
Showroom besuchen.
Sie möchten die Erlebnisstation selbst ausprobieren? Gerne laden wir Sie in unseren Showroom ein oder zeigen die Station auf Ihrer Veranstaltung oder Messe. Für Anfragen erreichen Sie uns per E- Mail: info@digitalzentrum.berlin.